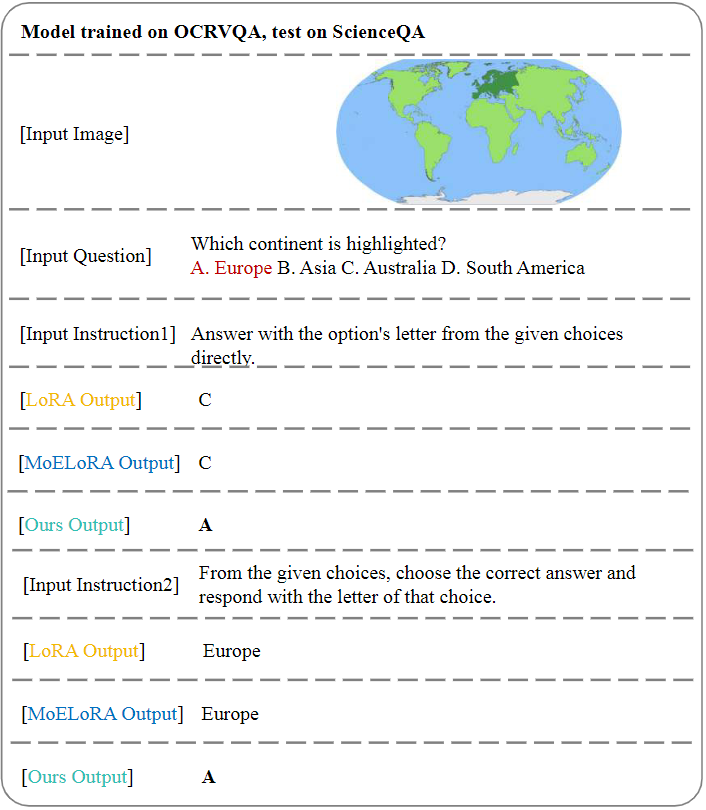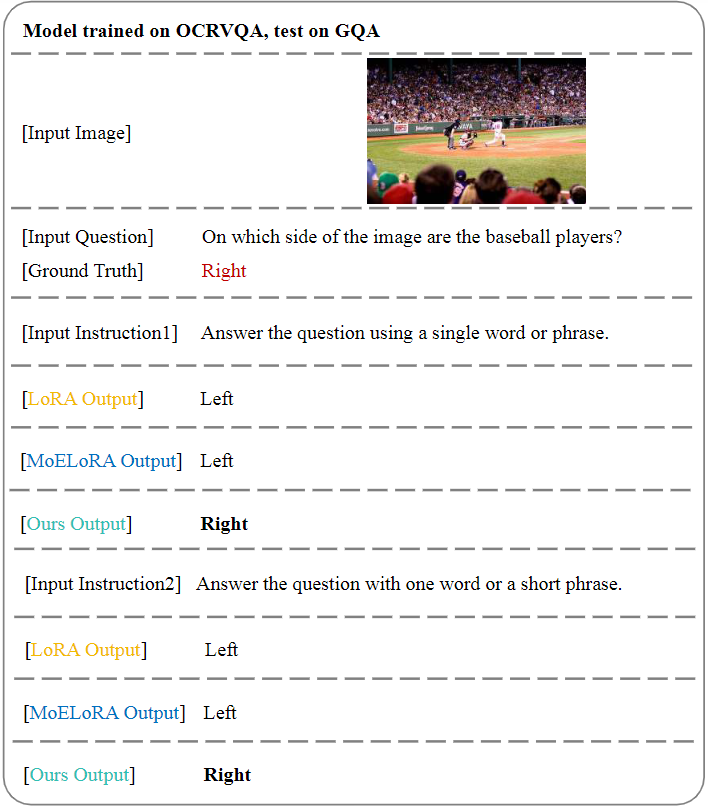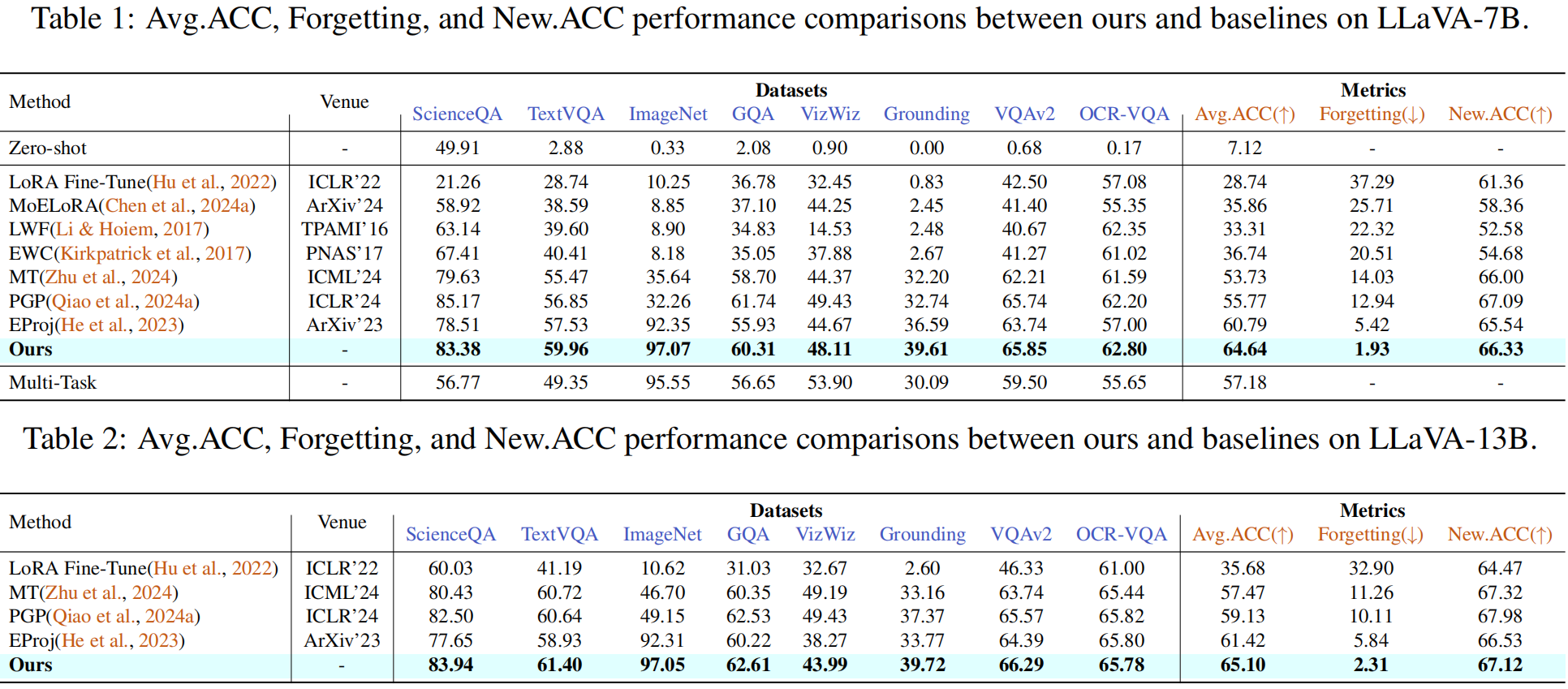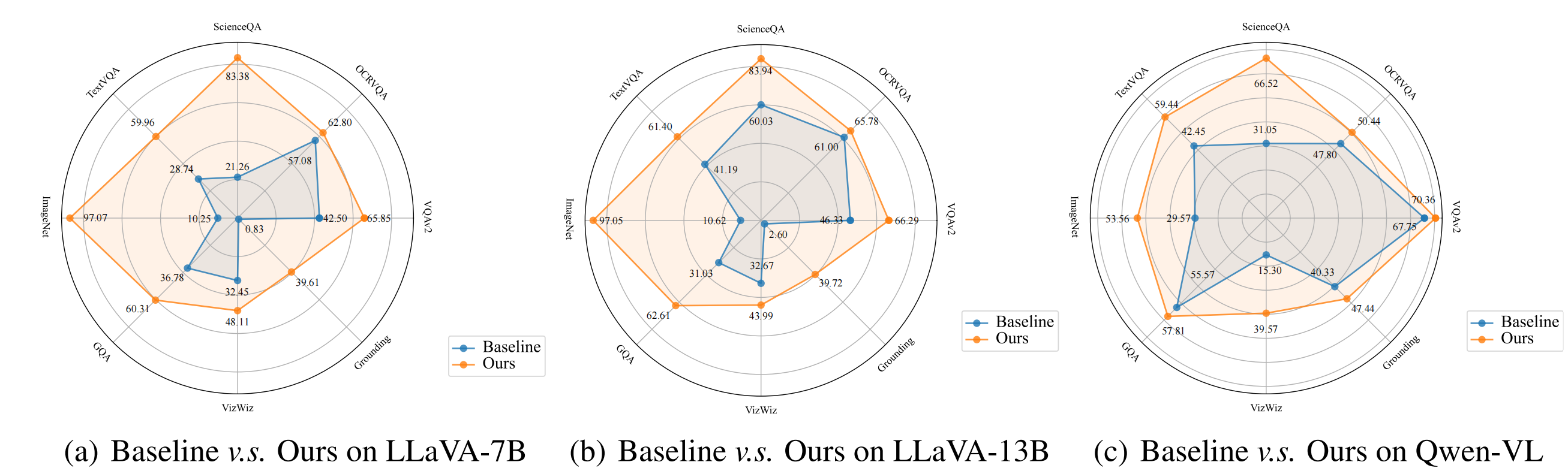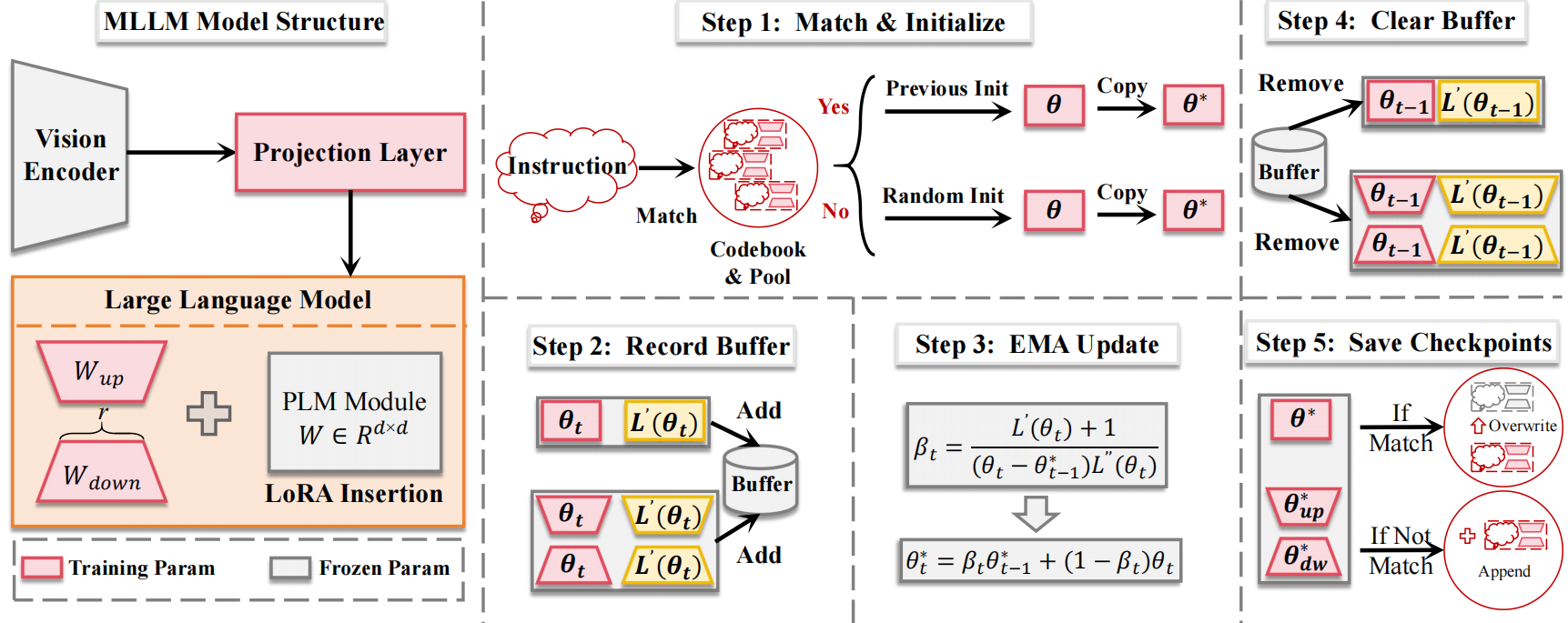
Case 1: Extreme Ironing

LLaVA-LoRA (After continually fine-tuned on six datasets)
Human: Can you describe the image?
Assistant: In the image, a man is standing on the back of a yellow truck, holding a clothesline with clothes hanging on it. He appears to be washing clothes in the middle of a busy street. The truck is driving down the road, and there are other vehicles around, including a taxi and a car.
There are also several traffic lights visible in the scene, indicating that the area is likely a busy intersection. The man is focused on his task, despite the bustling environment around him.
Human: Do you think there is anything that goes against human intuition?
Assistant: Yes, the image of a man washing clothes in the middle of a busy street goes against human intuition. Typically, people would expect to see someone washing clothes in a more private or secluded area, such as a backyard or a laundromat. However, in this case, the man has chosen to wash clothes in the middle of a busy street, which is an unusual and unconventional location for such an activity.
LLaCA-ours (After continually fine-tuned on six datasets)Human: Can you describe the image?
Assistant: In the image, a man is standing on a folding chair in the back of a yellow taxi cab, ironing clothes. The taxi is driving down a busy city street, surrounded by other vehicles such as a car and a truck. The man appears to be focused on his task, possibly trying to dry his clothes quickly in the moving vehicle.
Human: Do you think there is anything that goes against human intuition?
Assistant: Yes, the image of a man ironing clothes in the back of a taxi cab is unusual and goes against human intuition. It is not a typical scenario one would expect to see, as ironing clothes is usually done in a more comfortable and controlled environment, such as a home or a laundry room. The man's decision to iron clothes in the back of a taxi cab suggests that he is trying to save time or that he might be in a hurry.
LLaVA-original (w/o fine-tuning)Human: Can you describe the image?
Assistant: The image captures a busy city street scene with a man standing on a folding chair, holding a blue shirt and ironing clothes. He is positioned near the center of the scene, with a yellow car driving by in the background.
There are multiple vehicles on the street, including a taxi cab and a truck. The taxi is located on the left side of the scene, while the truck is further down the street, closer to the right side. The man is focused on his task, and the overall atmosphere suggests a bustling urban environment.
Human: Do you think there is anything that goes against human intuition?
Assistant: Yes, there are several examples of things that go against human intuition. Some of these include:
1. The illusion of motion: When an object moves quickly, our brain perceives it as a continuous motion, even though it is actually a series of discrete positions. This illusion is responsible for the motion blur effect in photographs.
2. The perception of time: Time is a relative concept, and our perception of it can be influenced by various factors, such as the speed of light, the rotation of the Earth, and the position of the observer relative to the Earth's surface.
3. The apparent size of objects: The size of objects can be distorted due to factors like distance, angle, and perspective. For example, when looking at a distant object, it appears larger than it actually is, and this effect is known as the "perspective illusion."
4. The perception of color: Color is a subjective experience, and our perception of it can be influenced by factors like lighting, the presence of colorants, and the specific wavelengths of light that are being reflected or emitted.
5. The perception of depth: Our brain creates a sense of depth by combining information from multiple sources, such as the position of objects relative to each other and the distance between them. This process can lead to misinterpretations of depth, as seen in the famous "duck-rabbit" optical illusion.
These examples demonstrate how our perceptions can be influenced by various factors and can lead to misunderstandings or misinterpretations of the world around us.